使用其他 LLM、其他 VectorDB 为 SQLite 生成 SQL¶
本 Notebook 介绍了使用 vanna Python 包通过 AI(RAG + LLMs)生成 SQL 的过程,包括连接数据库和训练。如果你还没准备好在自己的数据库上进行训练,仍然可以使用示例 SQLite 数据库 进行尝试。
你想使用哪个 LLM?
你想在哪里存储“训练”数据?
-
Vanna 托管的 Vector DB(推荐)免费使用 Vanna.AI 托管的向量数据库 (pgvector)。这可以在不同机器上使用,无需额外设置。
-
ChromaDB免费在本地使用 ChromaDB 开源向量数据库。无需额外设置——所有数据库文件都将在本地创建和存储。
-
Marqo免费在本地使用 Marqo。需要额外设置。或者使用他们的托管选项。
-
[Selected] 其他 VectorDB使用任何其他向量数据库。需要额外设置。
设置¶
In [ ]
%pip install vanna
In [ ]
from vanna.base import VannaBase
In [ ]
class MyCustomVectorDB(VannaBase):
def add_ddl(self, ddl: str, **kwargs) -> str:
# Implement here
def add_documentation(self, doc: str, **kwargs) -> str:
# Implement here
def add_question_sql(self, question: str, sql: str, **kwargs) -> str:
# Implement here
def get_related_ddl(self, question: str, **kwargs) -> list:
# Implement here
def get_related_documentation(self, question: str, **kwargs) -> list:
# Implement here
def get_similar_question_sql(self, question: str, **kwargs) -> list:
# Implement here
def get_training_data(self, **kwargs) -> pd.DataFrame:
# Implement here
def remove_training_data(id: str, **kwargs) -> bool:
# Implement here
class MyCustomLLM(VannaBase):
def __init__(self, config=None):
pass
def generate_plotly_code(self, question: str = None, sql: str = None, df_metadata: str = None, **kwargs) -> str:
# Implement here
def generate_question(self, sql: str, **kwargs) -> str:
# Implement here
def get_followup_questions_prompt(self, question: str, question_sql_list: list, ddl_list: list, doc_list: list, **kwargs):
# Implement here
def get_sql_prompt(self, question: str, question_sql_list: list, ddl_list: list, doc_list: list, **kwargs):
# Implement here
def submit_prompt(self, prompt, **kwargs) -> str:
# Implement here
class MyVanna(MyCustomVectorDB, MyCustomLLM):
def __init__(self, config=None):
MyCustomVectorDB.__init__(self, config=config)
MyCustomLLM.__init__(self, config=config)
vn = MyVanna()
你想查询哪个数据库?
-
Postgres
-
Snowflake
-
BigQuery
-
[Selected] SQLite
-
其他数据库使用 Vanna 为任何 SQL 数据库生成查询
In [ ]
vn.connect_to_sqlite('my-database.sqlite')
训练¶
你只需要训练一次。除非想添加更多训练数据,否则无需再次训练。
In [ ]
df_ddl = vn.run_sql("SELECT type, sql FROM sqlite_master WHERE sql is not null")
for ddl in df_ddl['sql'].to_list():
vn.train(ddl=ddl)
In [ ]
# The following are methods for adding training data. Make sure you modify the examples to match your database.
# DDL statements are powerful because they specify table names, colume names, types, and potentially relationships
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS my-table (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
)
""")
# Sometimes you may want to add documentation about your business terminology or definitions.
vn.train(documentation="Our business defines OTIF score as the percentage of orders that are delivered on time and in full")
# You can also add SQL queries to your training data. This is useful if you have some queries already laying around. You can just copy and paste those from your editor to begin generating new SQL.
vn.train(sql="SELECT * FROM my-table WHERE name = 'John Doe'")
In [ ]
# At any time you can inspect what training data the package is able to reference
training_data = vn.get_training_data()
training_data
In [ ]
# You can remove training data if there's obsolete/incorrect information.
vn.remove_training_data(id='1-ddl')
询问 AI¶
每当你提出新问题时,它将找到 10 个最相关的训练数据片段,并将其作为 LLM 提示的一部分来生成 SQL。
In [ ]
vn.ask(question=...)
启动用户界面¶
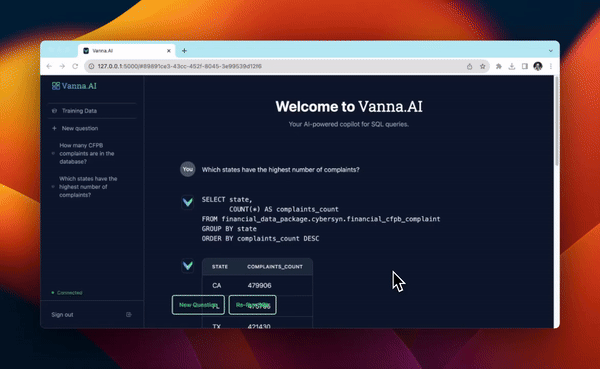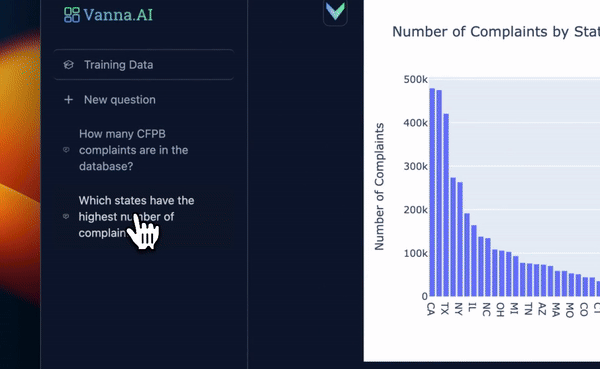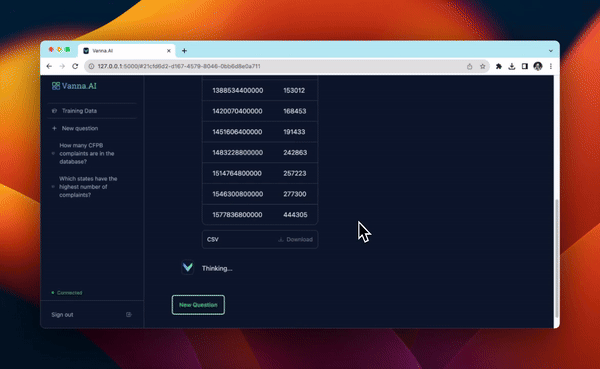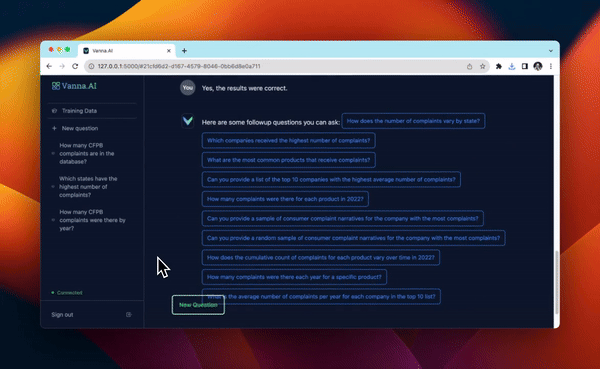
In [ ]
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()
