AI SQL准确度:测试不同的LLM + 上下文策略以最大化SQL生成准确度
2023-08-17
内容概要
拥有一个能够回答业务用户普通英文问题的自主AI代理的承诺具有吸引力,但迄今为止仍难以实现。许多人曾尝试让ChatGPT编写SQL,但收效甚微。失败的主要原因在于大型语言模型(LLM)缺乏对其需要查询的特定数据集的了解。
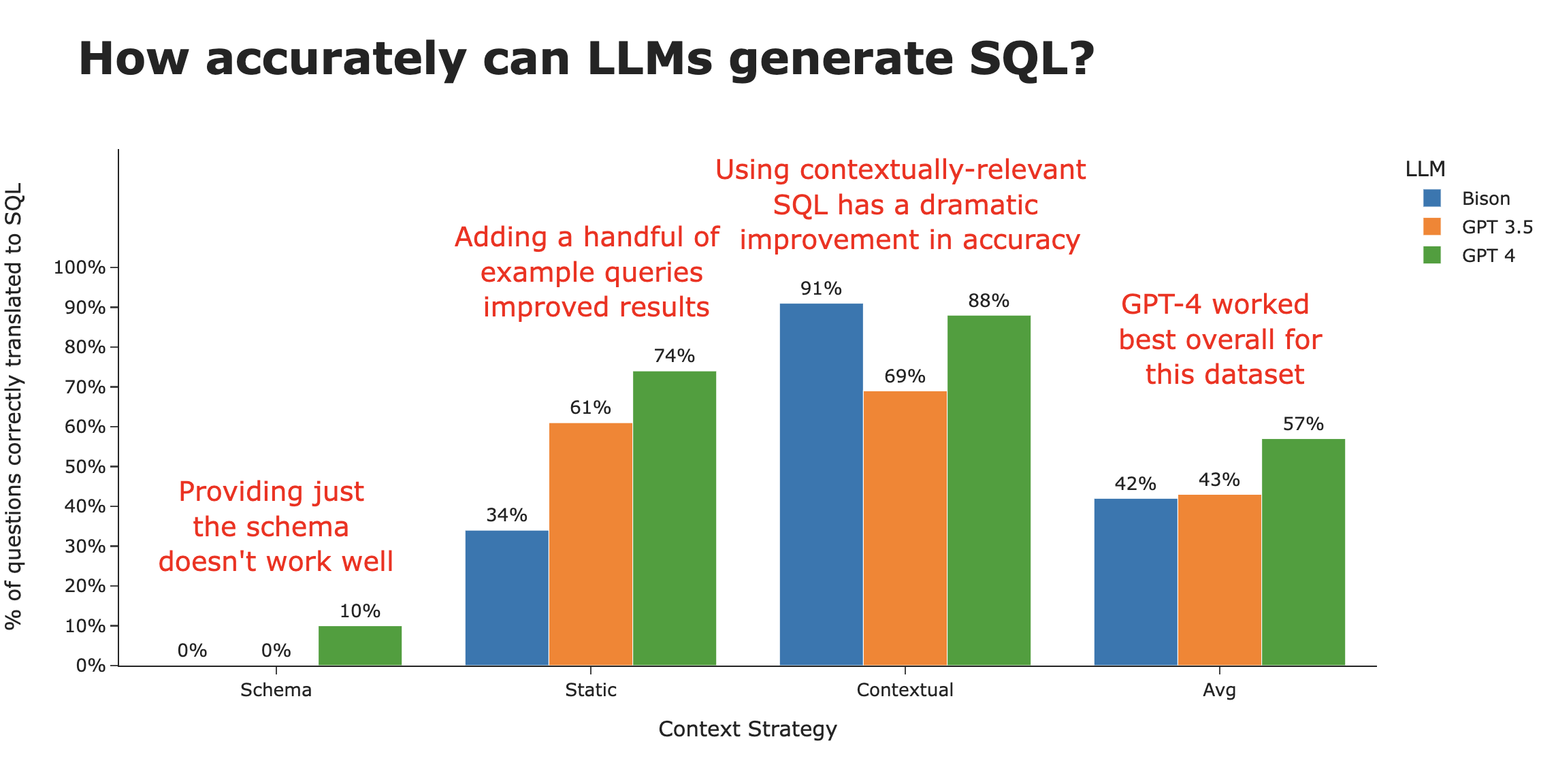
在本文中,我们展示了上下文至关重要,并且通过正确的上下文,我们可以将准确率从约3%提高到约80%。我们探讨了三种不同的上下文策略,并展示了其中一种明显的赢家——我们将模式定义、文档和先前的SQL查询与相关性搜索结合起来。
我们还比较了几种不同的LLM,包括Google Bison、GPT 3.5、GPT 4,并简要尝试了Llama 2。虽然GPT 4在生成SQL方面总体上表现最佳,但当提供足够的上下文时,Google的Bison大致相当。
最后,我们将展示如何使用本文演示的方法为您的数据库生成SQL。
以下是我们关键发现的摘要 -
目录
- 为什么使用AI生成SQL?
- 测试架构设置
- 测试因素设置
- 使用ChatGPT生成SQL
- 仅使用模式
- 使用SQL示例
- 使用情境相关示例
- 结果分析
- 进一步提高准确度的后续步骤
- 使用AI为您的数据集编写SQL
为什么使用AI生成SQL?
许多组织现已采用某种形式的数据仓库或数据湖——一个存储组织大量关键数据并可用于分析查询的存储库。这片数据海洋蕴藏着巨大的潜在洞察力,但企业中只有一小部分人具备利用这些数据所需的两项技能——
- 扎实的高级SQL理解能力,以及
- 对组织独特数据结构和模式的全面了解
同时具备上述两项技能的人不仅少之又少,而且很可能不是提出大部分问题的人。
那么组织内部实际发生了什么?业务用户,如产品经理、销售经理和高管,会有用于指导业务决策和战略的数据问题。他们会首先查看仪表盘,但大多数问题是临时且具体的,答案无法直接获得,因此他们会向具备上述技能组合的数据分析师或工程师寻求帮助。这些人很忙,处理请求需要一段时间,而且一旦获得答案,业务用户又会提出后续问题。
这个过程对双方来说都很痛苦:对业务用户而言(获得答案的等待时间长),对分析师而言(分散了他们的主要项目),这导致许多潜在的洞察丢失。
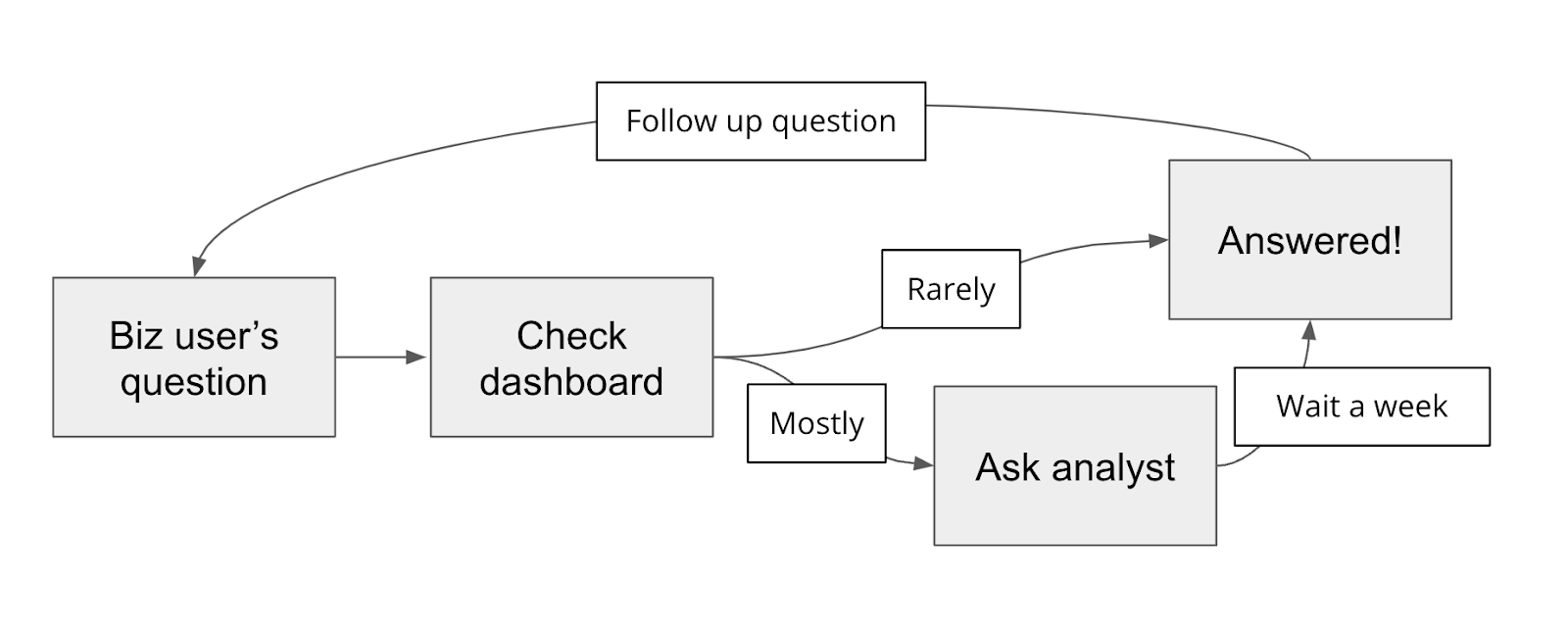
生成式AI登场!大型语言模型(LLM)可能为业务用户提供了用普通英语查询数据库的机会(由LLM完成SQL翻译),我们已经从数十家公司听说这将彻底改变他们的数据团队甚至整个业务的状况。
关键挑战在于为复杂且混乱的数据库生成准确的SQL。许多与我们交流过的人尝试使用ChatGPT编写SQL,但效果有限且痛苦不堪。许多人已经放弃并回归到手动编写SQL的传统方式。充其量,ChatGPT有时只能作为分析师纠正语法的一个有用副驾驶。
但希望还是有的!在过去的几个月里,我们深入研究了这个问题,尝试了各种模型、技术和方法来提高大型语言模型生成的SQL的准确性。在本文中,我们展示了各种LLM的性能,以及如何通过向LLM提供情境相关的正确SQL的策略,使其达到极高的准确性。
测试架构设置
首先,我们需要定义测试的架构。下面是大致的轮廓,一个五个步骤的过程,并附有伪代码 -
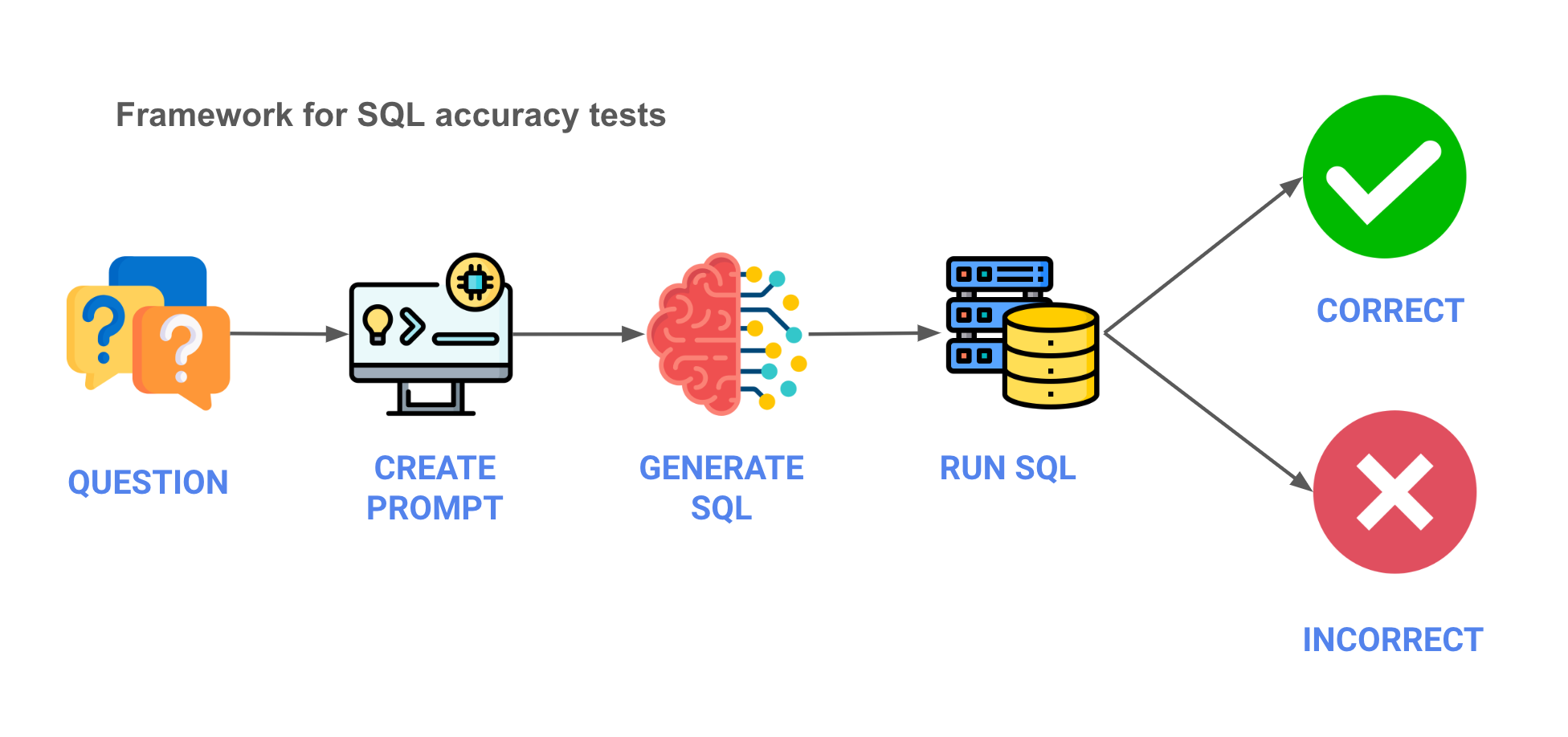
- 问题 - 我们从业务问题开始。
question = "how many clients are there in germany"
- 提示词 - 我们创建要发送给LLM的提示词。
prompt = f"""
Write a SQL statement for the following question:
{question}
"""
- 生成SQL - 使用API,我们将提示词发送给LLM并获取生成的SQL。
sql = llm.api(api_key=api_key, prompt=prompt, parameters=parameters)
- 运行SQL - 我们将在数据库中运行SQL。
df = db.conn.execute(sql)
- 验证结果 - 最后,我们将验证结果是否符合我们的预期。结果中存在一些模糊之处,因此我们对结果进行了手动评估。您可以在这里查看这些结果
测试因素设置
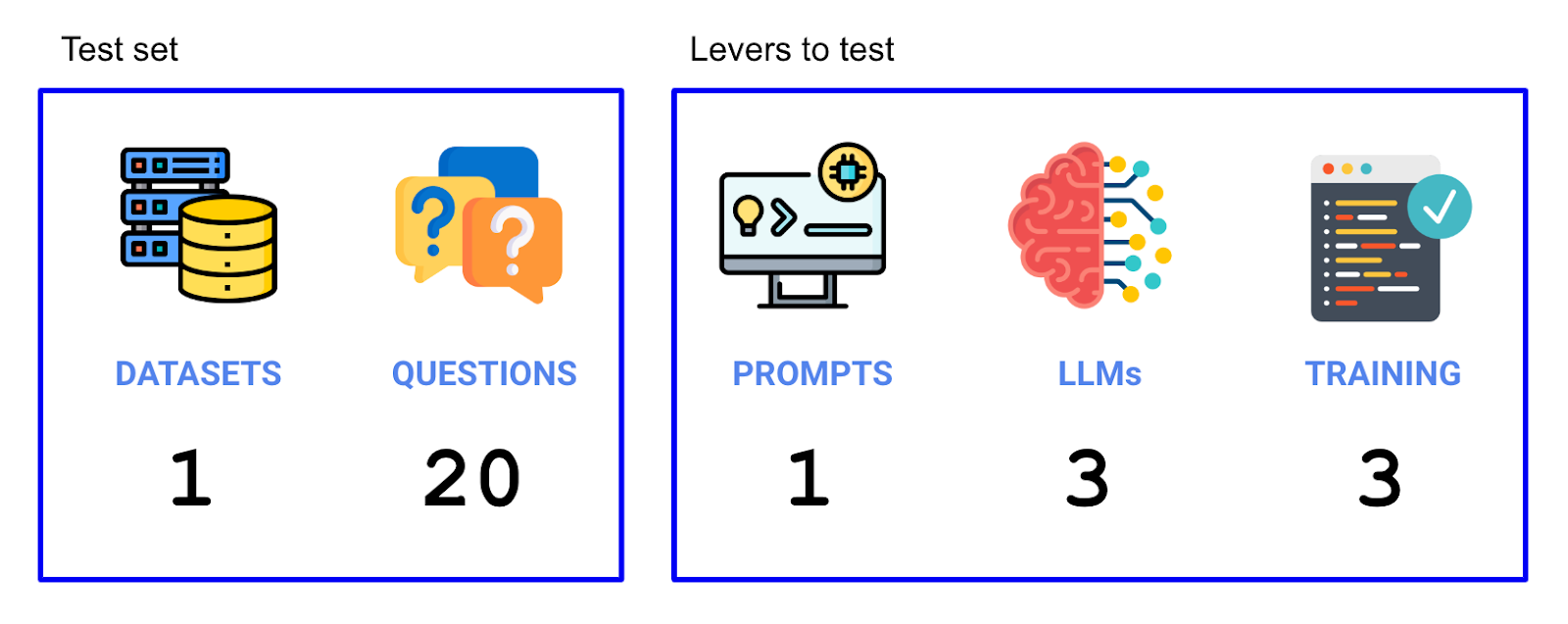
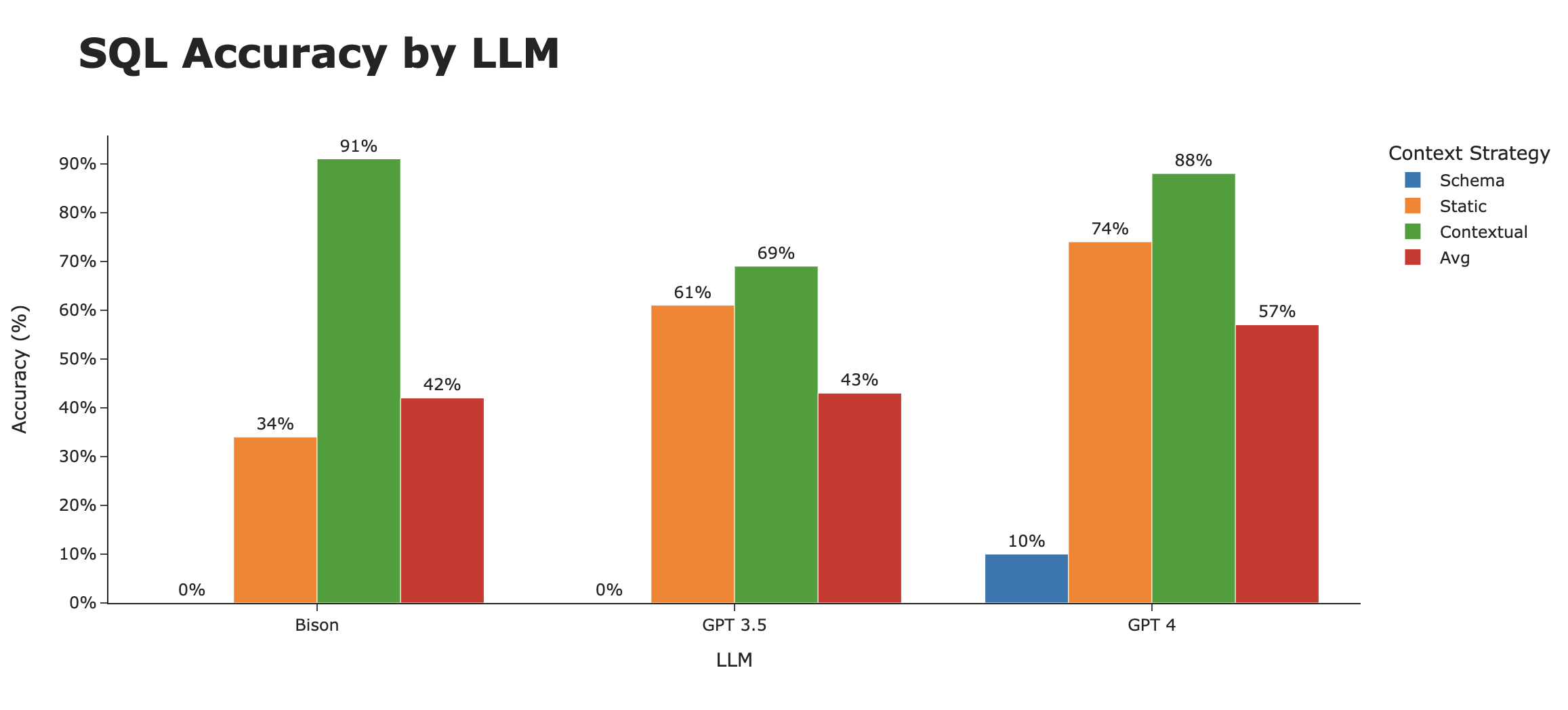
现在我们的实验已经设置好,我们需要确定哪些因素会影响准确性,以及我们的测试集是什么。我们尝试了两个因素(LLM和使用的训练数据),并在构成我们测试集的20个问题上进行了运行。因此,在此实验中,我们总共进行了 3个LLM x 3种上下文策略 x 20个问题 = 180个单独的试验。
选择数据集
首先,我们需要选择一个合适的数据集进行尝试。我们有一些指导原则 -
- 代表性。企业中的数据集通常很复杂,这种复杂性在许多演示/示例数据集中未能体现。我们希望使用一个具有真实世界用例并包含真实世界数据的复杂数据库。
- 可访问性。我们还希望该数据集是公开可用的。
- 易理解性。该数据集应该对广泛受众来说多少有些易于理解——任何过于小众或技术性的内容都将难以解读。
- 维护性。我们更喜欢一个被适当维护和更新的数据集,以反映真实数据库的情况。
我们发现符合上述标准的一个数据集是Cybersyn SEC filings数据集,该数据集在Snowflake市场免费提供
https://docs.cybersyn.com/our-data-products/economic-and-financial/sec-filings
选择问题
接下来,我们需要选择问题。以下是一些示例问题(可在此文件中查看全部) -
- 数据集中有多少家公司?
- 'ALPHABET INC.' 的损益表中可用的年度衡量指标有哪些?
- 特斯拉季度 '汽车销售' 和 '汽车租赁' 是多少?
- Chipotle目前有多少家餐厅?
现在我们有了数据集和问题,接下来需要确定影响因素。
选择提示词
对于提示词,本次运行我们将保持提示词不变,尽管我们会在后续进行变化提示词的跟踪研究。
选择LLM(基础模型)
对于待测试的LLM,我们将尝试以下几种 -
- Bison (Google) - Bison是PaLM 2的一个版本,可通过GCP API获得。
- GPT 3.5 Turbo (OpenAI) - 尽管GPT-4已经可用,但由于延迟和成本优势,GPT 3.5直到最近仍是OpenAI的旗舰模型,并且(好吧——我们将在测试中验证这一点)在准确性方面没有巨大差异,特别是对于基本任务。
- GPT 4 (OpenAI) - 更先进但性能稍逊的OpenAI模型。GPT 4是多模态的,尽管我们不会使用该功能。
- Llama 2 (Meta) - 我们非常想包含一个开源模型——而Meta的Llama 2是其中的佼佼者。但通过 Replicate 进行的设置很快就失效了,我们未能及时修复以进行发布。在我们早期运行时,当它确实能工作时,我们发现性能充其量只是中等水平。
选择上下文
最后,我们将使用三种类型的上下文。上下文是指我们发送给LLM的信息,这些信息有助于LLM理解我们特定的数据集。
- 仅模式。我们将模式(使用DDL)放入上下文窗口中。
- 静态示例。我们将静态的示例SQL查询放入上下文窗口中。
- 情境相关示例。最后,我们将最相关的上下文(SQL / DDL / 文档)放入上下文窗口中,通过基于嵌入的向量搜索来查找。
使用ChatGPT生成SQL
本节对ChatGPT有些不公平,但它是一个很好的起点。我们只是随便选取一个问题,然后让ChatGPT生成SQL -
提示词
Write Snowflake SQL to answer the following question -
What are the quarterly revenues by business segment for Alphabet?
Return SQL only
回应
当然,这是SQL查询
SELECT
EXTRACT(QUARTER FROM date_column) AS quarter,
business_segment,
SUM(revenue) AS quarterly_revenue
FROM
revenue_table
WHERE
company_name = 'Alphabet'
GROUP BY
quarter,
business_segment
ORDER BY
quarter,
business_segment;
-- Replace date_column, business_segment, revenue, revenue_table, and adjust any other identifiers to match your specific database schema.
不出所料,当我们尝试运行这段代码时,出现了错误,因为它在我们没有提供表名的情况下虚构了一个表名 -

当然,我们对LLM有些不公平——尽管它们很神奇,但它们(不幸?幸运?)不可能知道我们的数据库里有什么——至少目前是这样。所以,让我们开始进行提供更多上下文的测试。
仅使用模式
首先,我们获取数据集的模式并将其放入上下文窗口。这通常是我们看到人们在使用ChatGPT或在教程中做的事情。
一个示例提示词可能看起来像这样(实际上我们使用了信息模式,因为Snowflake的共享方式如此,但这展示了其原理) -
The user provides a question and you provide SQL. You will only respond with SQL code and not with any explanations.
Respond with only SQL code. Do not answer with any explanations -- just the code.
You may use the following DDL statements as a reference for what tables might be available.
CREATE TABLE Table1...
CREATE TABLE Table2...
CREATE TABLE Table3...
结果,一言以蔽之,太糟糕了。在60次尝试中(20个问题 x 3个模型),只有两个问题得到了正确回答(都由GPT 4完成),准确率低至3%。以下是GPT 4成功答对的两个问题 -
- 按频率计算,前10位的衡量指标描述是什么?
- 报告属性中有哪些不同的声明?
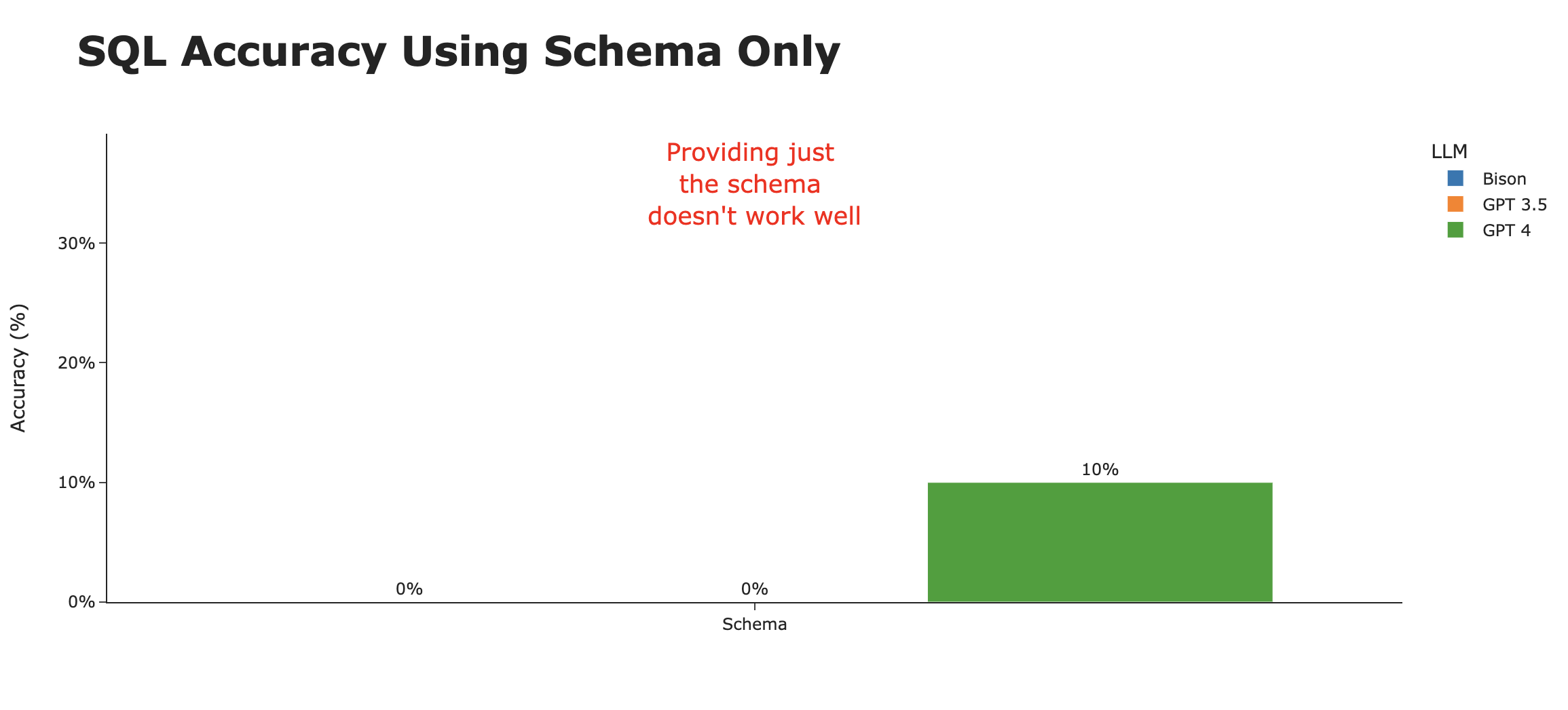
很明显,仅使用模式,我们离成为一个有用的AI SQL代理的标准还差得很远,尽管它可能在作为分析师的副驾驶方面有点用处。
使用SQL示例
如果我们站在一个第一次接触这个数据集的人的角度思考,除了表定义之外,他们首先会查看示例查询,看看如何正确查询数据库。
这些查询可以提供模式中没有的额外上下文——例如,使用哪些列,表如何连接,以及查询特定数据集的其他复杂细节。
与Snowflake市场上的其他数据提供商一样,Cybersyn在其文档中提供了一些(此处为3个)示例查询。我们将这些包含在上下文窗口中。
仅通过提供这3个示例查询,我们看到生成的SQL的正确性有了显著提高。然而,准确性因底层LLM而异。似乎GPT-4最能以生成最准确SQL的方式泛化示例查询。
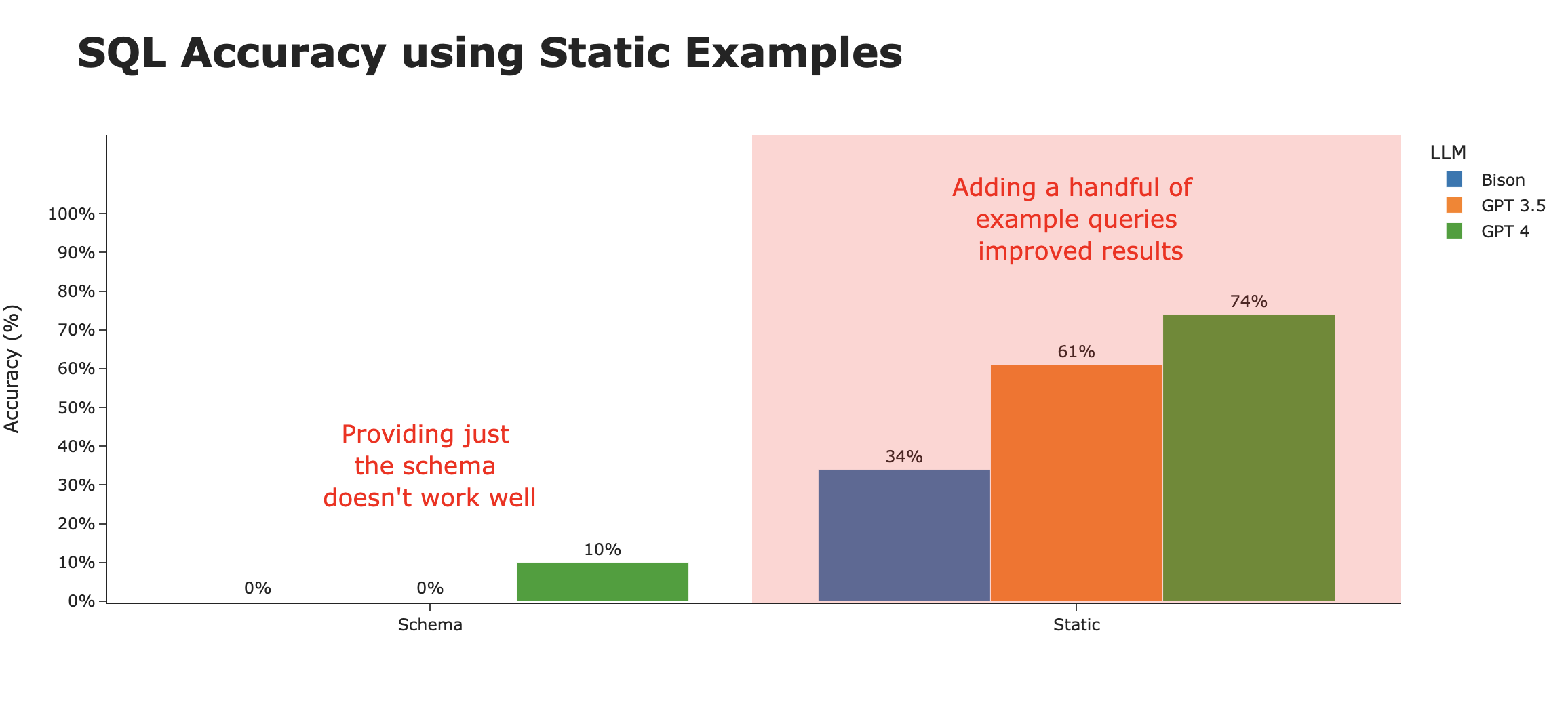
使用情境相关示例
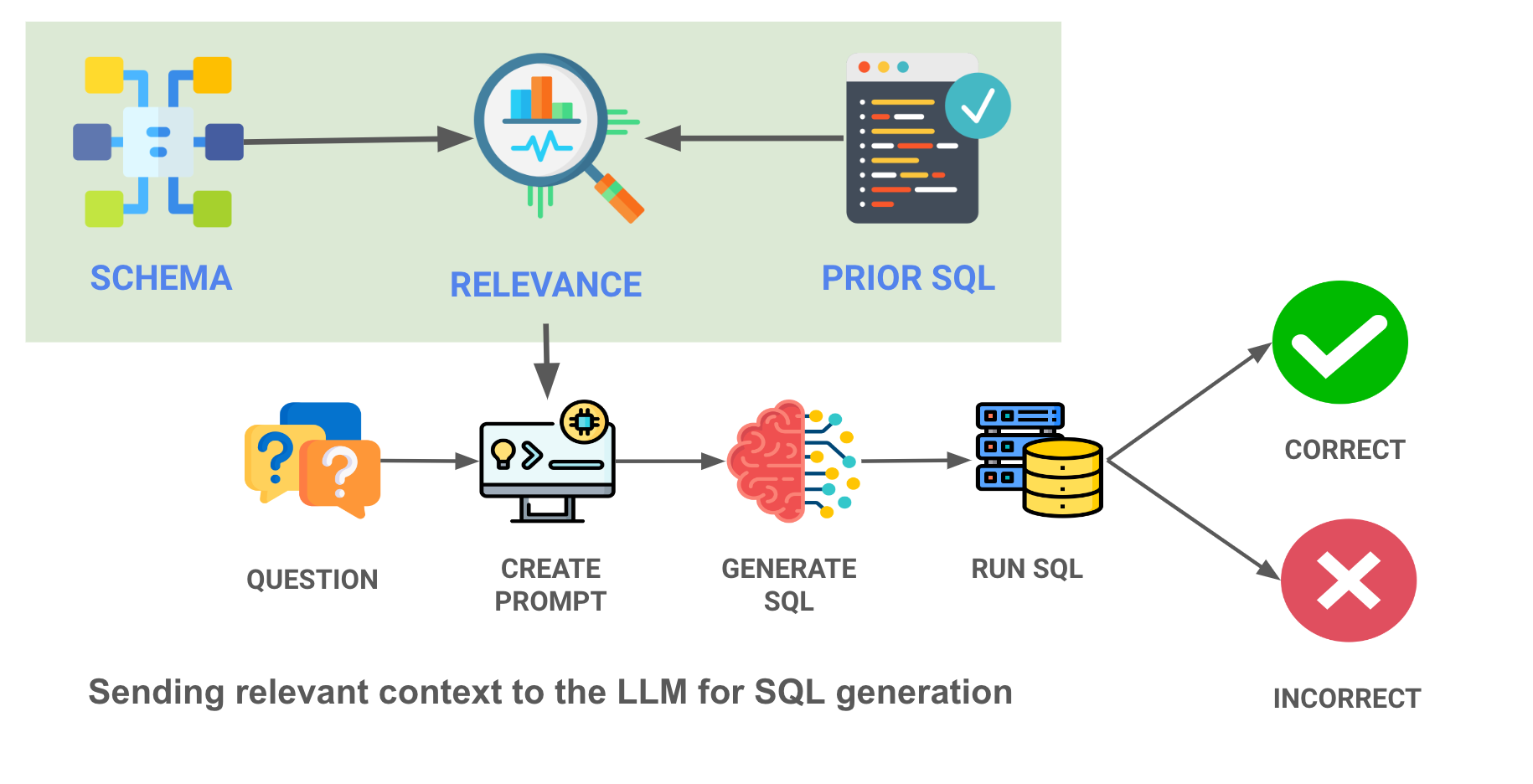
企业数据仓库通常包含数百个(甚至数千个)表,以及覆盖其组织内所有用例的更多查询。考虑到现代LLM有限的上下文窗口大小,我们不能简单地将所有先前的查询和模式定义都塞进提示词中。
我们处理上下文的最后一种方法是一种更复杂的机器学习方法——将先前的查询和表模式的嵌入加载到向量数据库中,并只选择与所提问题最相关的查询/表。这是我们正在做的事情的图示——注意红色框中的情境相关性搜索 -
通过向LLM展示最相关的SQL查询示例,我们可以显著提高即使是能力较弱的LLM的性能。在这里,我们为LLM提供了针对该问题的10个最相关的SQL查询示例(从存储的30个示例列表中选取),准确率因此飙升。
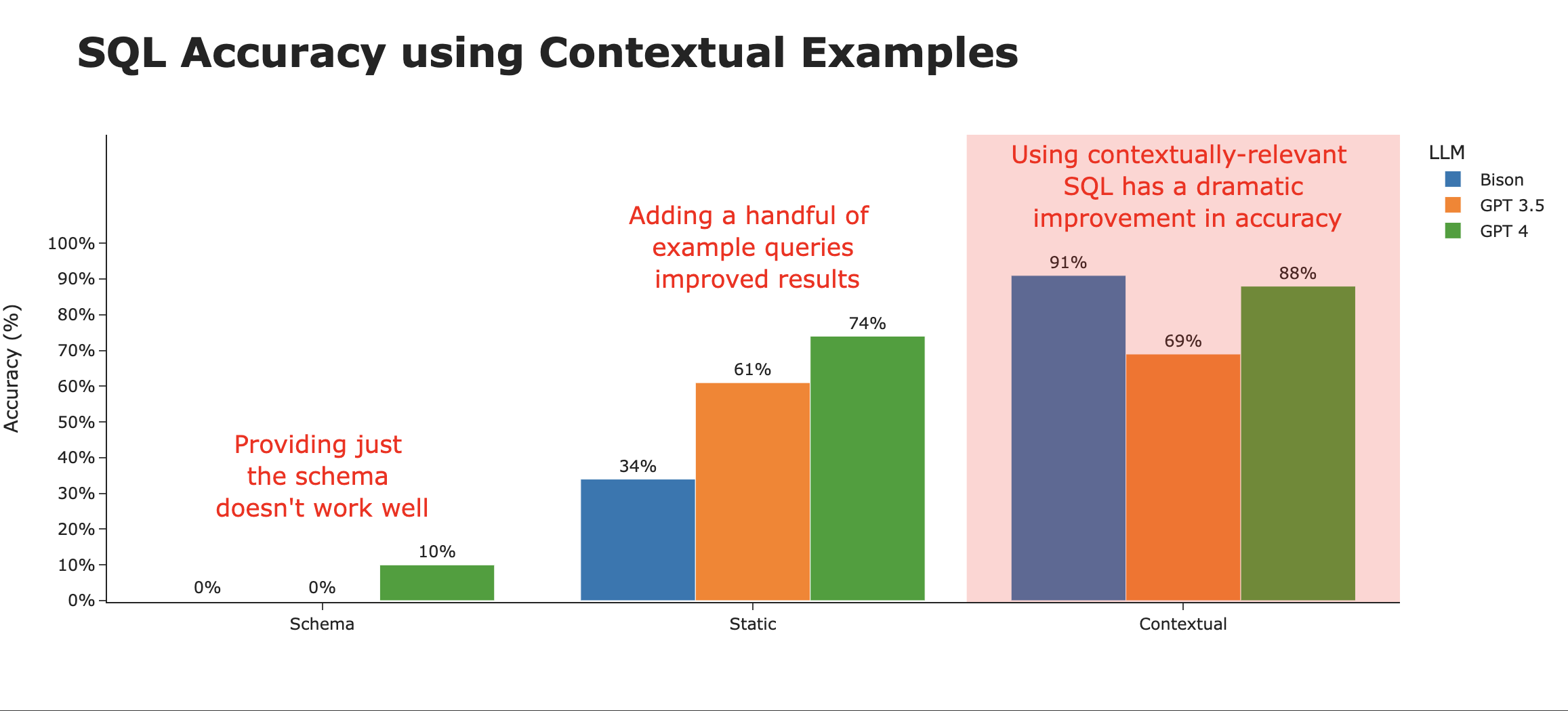
通过维护用户实际提出的、可执行且正确回答问题的SQL语句历史记录,我们可以进一步提高性能。
结果分析
很明显,最大的差异不在于LLM的类型,而在于向LLM提供适当上下文(例如所使用的“训练数据”)所采用的策略。

当我们按上下文策略查看SQL准确率时,很明显这就是造成差异的原因。仅使用模式时准确率约为3%,而智能地使用情境相关示例时,准确率可达约80%。
LLM本身仍然有一些有趣的趋势。虽然Bison在仅模式和静态上下文策略中都处于垫底位置,但在完整的上下文策略下却一跃成为顶尖。平均来看,在三种策略中,GPT 4荣膺SQL生成的最佳LLM。
进一步提高准确度的后续步骤
我们将很快对本次分析进行后续研究,以更深入地探讨准确的SQL生成。下一步包括 -
- 使用其他数据集:我们很想在其他真实世界的企业数据集上尝试这一点。当面对100个表?1000个表时会发生什么?
- 增加更多训练数据:虽然30个查询量不错,但当数量增加10倍、100倍时会发生什么?
- 尝试更多数据库:本次测试在Snowflake数据库上运行,但我们也已使其在BigQuery、Postgres、Redshift和SQL Server上工作。
- 尝试更多基础模型:我们已经接近能够使用Llama 2了,并且很想尝试其他LLM。
我们对上述内容有一些传闻证据,但我们将扩大和改进测试,以包含更多这些项目。
使用AI为您的数据集编写SQL
虽然SEC数据是一个好的开始,您一定想知道这是否与您自己的数据和组织相关。我们正在构建一个Python包,它不仅可以为您的数据库生成SQL,还提供额外的功能,例如能够为图表生成Plotly代码、生成后续问题以及各种其他功能。
以下是它的工作原理概述
import vanna as vn
- 使用模式训练
vn.train(ddl="CREATE TABLE ...")
- 使用文档训练
vn.train(documentation="...")
- 使用SQL示例训练
vn.train(sql="SELECT ...")
- 生成SQL
开箱即用使用Vanna最简单的方法是调用vn.ask(question="什么是..."),它将返回SQL、表格和图表,您可以在这个示例notebook中看到。vn.ask是vn.generate_sql、vn.run_sql、vn.generate_plotly_code、vn.get_plotly_figure和vn.generate_followup_questions的包装器。这将使用优化后的上下文为您的问题生成SQL,其中Vanna会为您调用LLM。
或者,您可以使用vn.get_related_training_data(question="什么是..."),如这个notebook所示,它将检索最相关的上下文,您可以使用这些上下文构建自己的提示词发送给任何LLM。
此notebook展示了如何使用“静态”上下文策略在Cybersyn SEC数据集上训练Vanna的示例。
术语说明
- 基础模型:这是底层的LLM
- 上下文模型(即Vanna模型):这是一个位于LLM之上并为LLM提供上下文的层
- 训练:通常当我们提到“训练”时,我们指的是训练上下文模型。
