基于 AI (LLM) 的 Python 开源 Text-to-SQL 工具
我们激动地宣布一个重要的里程碑:Vanna 现已作为开源软件包提供。这一举措是我们迈向普及 AI 驱动的 SQL 生成能力的关键一步。今天,我们将讨论 Vanna 帮助解决的挑战、我们为什么选择开源、如何在本地部署 Vanna 等等。
我们已经在 Github 上开源了包含我们大部分产品逻辑的 Python 软件包,但我们仍然有一个闭源服务器处理与 LLM 的接口和提供上下文的向量数据库,缺少一个开源的、可在本地运行的替代方案。这种情况将不复存在!
AI 生成 SQL 的挑战
与我们交流过的每个人都喜欢 AI 生成 SQL 的想法——随着数据复杂性和体积的不断增长,对简化查询的需求达到了前所未有的高度。传统的 SQL 查询生成通常耗时且需要大多数人不具备的专业技能。AI 生成 SQL 可以改变游戏规则,但它需要满足以下条件:
- 高准确率。 高准确率确保 AI 生成的 SQL 能够提供精确可靠的结果,并同时在技术用户和业务用户中建立信任。
- 易于训练。 系统必须能够根据企业的独特数据模式进行定制训练,以便量身定制,适应特定的内部数据结构。
- 安全。 确保安全性至关重要,因为 AI 生成的 SQL 必须保护敏感数据,并限制在非必要情况下将数据发送到公司生态系统之外。
我们在实现上述三个目标方面进展顺利(例如,请参阅我们关于提高准确率的白皮书)。我们相信开源 Vanna 将有助于实现上述所有目标。
我们为何开源 Vanna
我们出于几个关键原因选择开源 Vanna
- 安全性: 本地部署选项确保所有数据和查询都留在您的生态系统内,这在受监管或更规避风险的行业(如金融和医疗保健)中特别有用。
- 可定制性: 开源使用户可以更换存储和底层模型 (LLM),以满足其独特需求。
- 建立标准: 数据生态系统将受益于一个标准的开源库,该库随后可以根据各种需求进行定制。
本地部署 Vanna
本地部署 Vanna 是一个简单的过程。
您需要在您的机器上安装 Python 3.x 和 pip。以下代码将安装 Vanna,将其连接到本地定义的 LLM 调用,训练专用的 Vanna 模型,并以简单的英文提问:
%pip install 'vanna[chromadb,snowflake,openai]'
from vanna.local import LocalContext_OpenAI
vn = LocalContext_OpenAI({"api_key": "sk-..."})
vn.train(sql="...")
vn.ask()
关于 如何使用 Vanna 开源和本地部署选项的完整详情已在此处文档中说明 。
根据您的需求更换组件:简要概述
Vanna 被设计为可扩展和灵活的。我们的开源和本地可运行版本的 Vanna 提供了更换四种不同组件的能力。
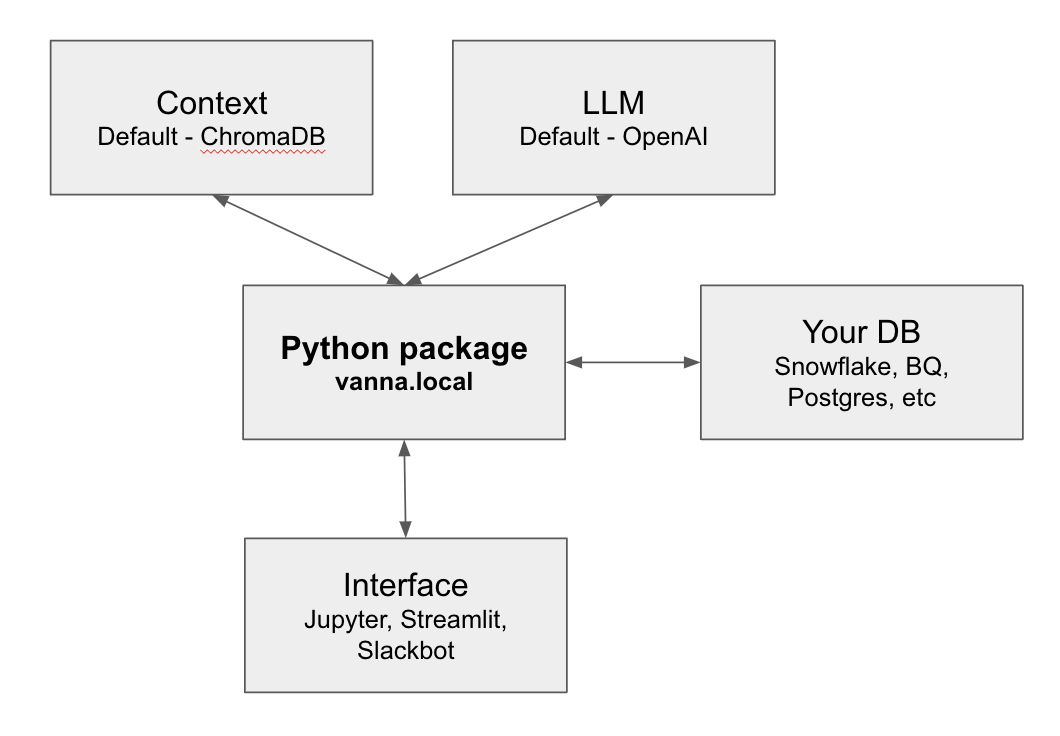
- 存储: Vanna 的模块化架构支持多种存储后端。您可以指定您的首选存储。默认是 ChromaDB,但您可以使用 Pinecone、带有 pgvector 扩展的 Postgres 或任何其他向量数据库。
- LLM: 许多用户可能希望尝试不同的 LLM。我们有一份 白皮书 比较了 GPT 4、GPT 3.5 和 Bard 的性能。您可以扩展此列表,甚至微调您自己的 LLM。
- 数据库: 您的数据库连接、模式和所有数据都完全保持在本地。您可以将 Vanna 配置为连接到任何数据库,但我们已经内置了 Snowflake 、 BigQuery 和 Postgres 的连接功能和教程。
- 接口: 虽然大多数用户开始时通过 Jupyter Notebook 使用 Vanna,但您也可以在本地运行的 Streamlit 应用 中使用它,或者托管您自己的 Slackbot 。这三个选项都可以配置为完全本地运行,无需与 Vanna 的服务器进行任何交互。
尽管这不是一个全面的指南,但 此处提供了详细文档 以帮助您进行这些定制。
本地版本与托管版本
哪种版本适合您? 在大多数情况下, 托管版本 仍然是更好的选择 ——它启动更快,性能更优越、功能更强大,并且管理开销更小。然而,在某些情况下——出于监管原因必须在本地运行一切,或者您需要特定且不受支持的存储/LLM 集成时,使用和修改开源版本是首选选项。这里有一个快速比较:
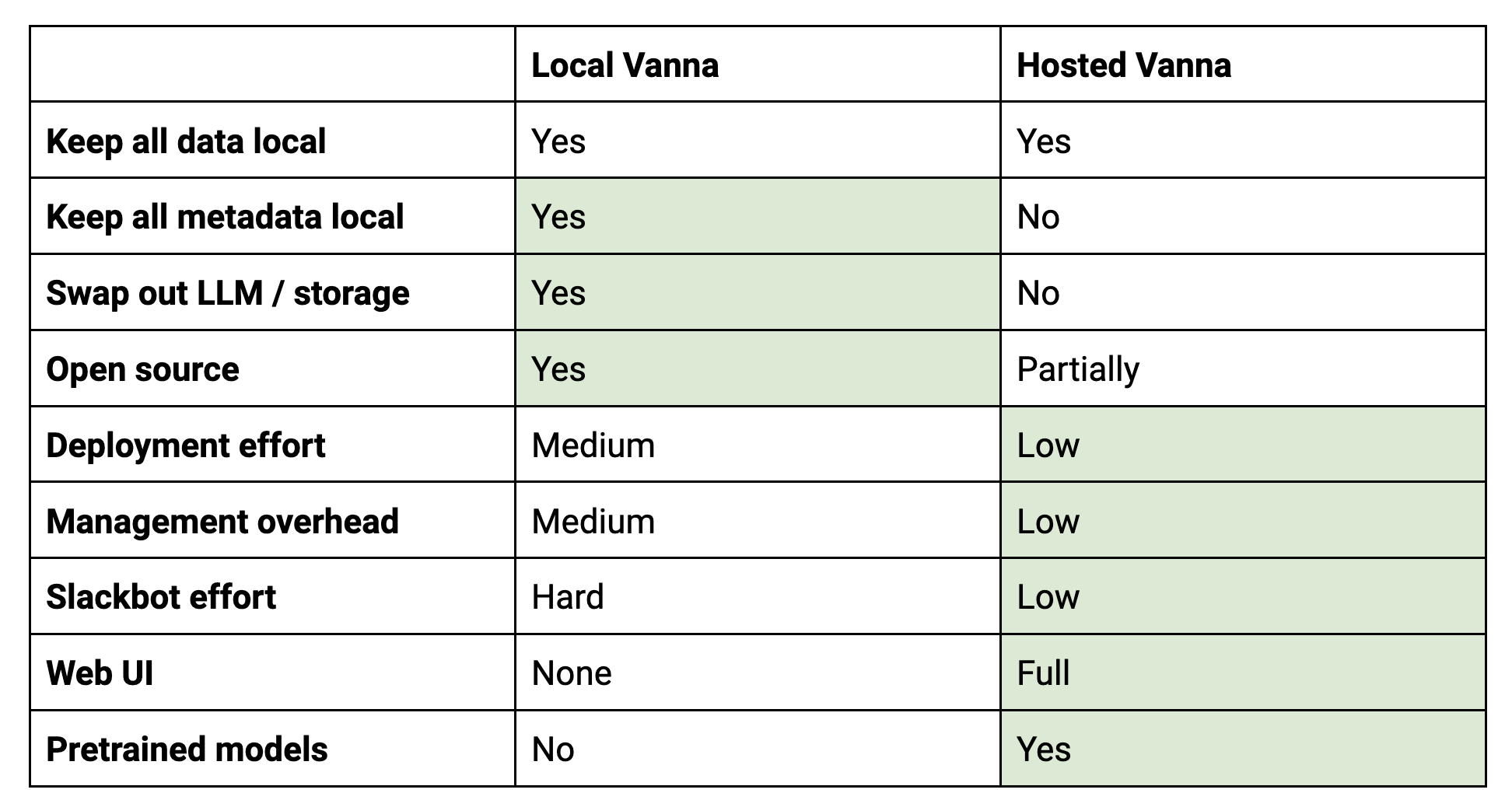
简而言之,如果您需要深度定制或处于受监管行业且拥有可用于 DevOps 的资源,本地版本更适合。如果您优先考虑额外功能和易用性,托管版本更适合。
贡献 Vanna 的开源版本
我们欢迎贡献者通过 Github 参与 Vanna 的开源项目 。无论您是开发者、数据科学家,还是对 AI 和 SQL 感兴趣的人,都有多种方式可以贡献:
- 代码贡献: 提交新功能或错误修复的拉取请求 (Pull Requests)。
- 文档: 帮助改进我们的用户指南和 API 文档。
- 功能建议: 分享您希望在未来版本中看到的功能。我们迫不及待地想看看社区如何将 Vanna 推向新的高度。您的贡献不仅会丰富项目,还将为构建一个更精简、高效且可定制的 AI 生成 SQL 生态系统铺平道路。
总结
通过开源 Vanna,我们旨在围绕 AI 生成 SQL 创建一个繁荣的社区,倡导协作、定制和创新。通过试用 Vanna、为其发展贡献力量,并让数据查询对每个人来说都更轻松高效,加入我们这个激动人心的旅程吧。
更多详情和入门指南,请 访问我们的文档 。
愉快地查询(呃,提问)!
